Lokad Platform
On the surface, Lokad looks like a small webapp. It has noticeably less buttons, menus, and options than what most people would expect from a business app. Yet, this simplicity is deceptive as Lokad is fairly capable. It offers the possibility to build data pipelines featuring tons of data, machine learning algorithms, numerical optimization and detailed reports. Thus, in this section, we provide an initial review of all these components that will be explored in greater detail later on.
Table of contents
The File System
Lokad stores and processes data that lies in a local file system, i.e. folders and files. This file system can be accessed through the Files tab within a Lokad account. This file system is intended to collect all (transactional) data originating from the ERP / MRP / WMS / etc., pushed toward Lokad as flat text files. It is possible to upload files from the web, however, files are usually pushed through file transfer protocols like FTPS or SFTP.
Under the hood, this file system is quite different from regular file systems. First, files are distributed (i.e. data spread over multiple machines), both for redundancy and performance purposes. Second, it’s technically much more like Git (a version-control system) than a regular file system, except it’s intended for giganormous flat files.
File versioning is essential in order to reproduce and troubleshoot problems, even if the underlying data has changed, typically because of an automated file transfer process. Strict atomicity at the file level also eliminates entire classes of problems, such as mistakenly processing files while they are being written. This also creates many complications when dealing with protocols like FTPS or SFTP that the file system transparently addresses.
In most situations, the file system is Lokad’s API (Application Programming Interface), using FTPS or SFTP. Indeed, moving files around is where the complexity lies. However, implementing high performance, reliable (recover on error) web APIs is difficult both on the client side and server side. File transfer protocols are practical and widely available.
The Project Explorer
The project explorer gathers, as the name suggests, all the projects in Lokad: Envision scripts, run sequences and data source syncers. This explorer can be accessed through the Projects tab in the Lokad account. It offers hierarchical navigation - much like the file system - but gathering all the non-data pieces within the Lokad account.
The explorer hierarchy has two purposes: first, to facilitate the organization of complex accounts that hold many projects, second, to support the ACLs (Access Control List) used to decide who can see what (or do what) within the account.
All projects can be run through the explorer. By design, the platform is safe against concurrent runs: a script cannot consume the half-way written outputs produced by another script, similarly two scripts overwriting the same files will not result in corrupted outputs (also one script will get its outputs fully and cleanly overwritten). Any run can be cancelled, and cancellations are also safe, i.e. no partial write’s leftovers: either a run completes, or it doesn’t.
The Dashboard View
When an Envision script is run, it has two distinct outputs: a web view, referred to as a “dashboard”, which always exists and, possibly, output files that might have been written (depending on the script itself). Dashboards are intended for a broad audience within the company, not just a technical audience.
The dashboarding system of Lokad revolves around the notion of tiles. A single dashboard can include many tiles that are positioned in a grid system à la Excel. Lokad emphasizes the practice of packing all the relevant information together, to largely remove the need to “hop” from one dashboard to the next, due to dispersed information.
show scalar "red" a1b2 { backgroundColor: #d0021b } with poisson(1)
show scalar "blue" c1d4 { backgroundColor: #4a90e2 } with poisson(2)
show scalar "green" a3b4 { backgroundColor: #7ed321 } with poisson(3)
Each dashboard comes with its own history that includes all the previous runs. Past versions of the dashboard remain accessible - as well as their file outputs. This feature is intended for troubleshooting purposes such as investigating the root causes behind a past reorder quantity.
The Code Editor
The code editor (“editor” in the following) is, as the name suggests, intended for the editing of the Envision scripts. This editor isn’t just about code coloring, it delivers the capabilities expected from a modern development environment: renaming variables, identifying dead code, displaying user-defined documentation, etc.
Supply Chain Scientists are the intended audience for the editor. Regular end-users who only consume the app(s) built on top of the platform aren’t typically expected to interact with the editor. Then, in order to avoid accidental editing of the scripts, Lokad offers the possibility to choose when a user has Edit rights or not.
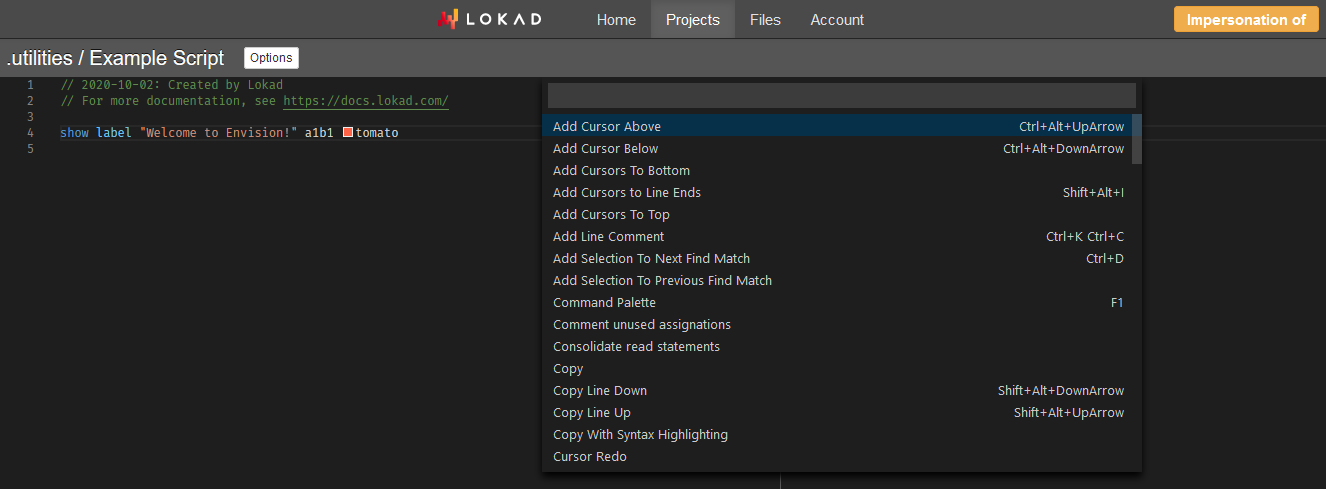
Upon first contact with the editor, the most important feature is the F1 keyboard shortcut for the command palette. The command palette lists all the available commands along with their shortcuts (when they have one).
The Distributed Runtime
The least visible component of Lokad is also the most complex one: the runtime system, that is the backend system that takes care of running (i.e. executing) Envision scripts. Although we use the term script rather than source code to emphasize that Envision is a high-level programming language, the scripts are compiled to machine code for performance.
Beware, the runtime system should not be confused with the runtime lifecycle phase of a script during, which is when the runtime system is in operation. For example, the Envision compiler attempts to capture as many problems as possible at compile time in order to avoid discovering them at runtime, i.e. when the runtime system is in operation.
Our runtime is distributed: scripts processing large amounts of data typically end-up run on multiple machines. This behavior allows us to reduce the wall-clock time it takes to complete a run. Under the hood, unlike regular programming languages, Envision is directly compiled targeting distributed computing resources (instead of targeting a single machine).
Lokad has developed its own runtime system focusing on data parallelism and fault tolerance. However, compared to mainstream Big Data options, there are several differences that make Lokad rather special:
- performance-wise, our runtime benefits from a whole-stack integration that is difficult to achieve when third party code has to be executed outside the runtime.
- feature-wise, our runtime integrates specialized machine learning blocks as first class citizens, for example differentiable programming, not through distinct frameworks.
- security-wise, our runtime is tight, and does not allow interleaving general-purpose code that is difficult to sandbox in practice.
Finally, our runtime is geared toward improving the productivity of the Supply Chain Scientists themselves. Indeed, when working with a large dataset, scripts are typically written a few lines at a time, re-running small incremental variations of the same script many times. Our runtime extensively leverages caching techniques of intermediate results to ensure that only the parts that have changed from one script version to another get recomputed.
Under the hood
This subsection is intended for a software engineer audience. It can safely be skipped.
Our runtime is internally implemented in .NET Core with a mix of F# and C#, leveraging low-level hardware capabilities such as intrinsics (SIMD) and on-stack memory (i.e. System.Span). Our runtime shares many similarities with Apache Spark. Our file system is a content addressable store, with many specificies geared toward the columnar data processing model that permeates both the language (Envision) and its runtime.
Nearly everything above .NET, including the machine learning elements, has been (re)implemented by Lokad. We do not use third party SQL databases or Big Data frameworks. Indeed, performance, reliability and security problems arise at the system boundaries. Thus, Lokad decided to remove those boundaries altogether, through an integrated stack, centrally engineered around its compiler.
Lokad co-versions both the data files and the scripts, allowing the runtime to re-execute scripts in the exact conditions that were present at any point in the past. This feature is critical to debug complex data pipelines where data gets automatically refreshed. Without this, too many problems end-up as heisenbugs : by the time somebody can have a look at it, the problem is gone, but the problem keeps sporadically reappearing in production.
External data sources
Lokad supports built-in data connectors for a few popular apps. Those applications have in common exposing APIs that make it possible for a third-party like Lokad to automatically extract their data. The data of prime interest for supply chain purposes is the core transactional data, which typically exists in most ERPs:
- Product catalog and/or list of SKUs
- Sales order history (ideally disaggregated)
- Purchase order history (idem, disaggregated)
- Stock on hand, stock on order
- Selling prices and buying prices, MOQs
- …

In our experience, retrieving reliably and quickly all the data we need - the bulk of it being plain transactions - from external sources tends to be surprisingly difficult. Most of the APIs out there do not really qualify as “production-grade”. The main issues that Lokad faces when engineering a data connector are:
- Dramatically slow APIs (facing 1 request / second is not infrequent)
- Dealing with downtime and transient API errors
- Lack of proper mechanisms for incremental data retrieval
- Lack of documentation to clarify the semantic of the data
In practice, even if we do support a business app, making the data retrieval work may require some coordination between Lokad’s software engineering team, and the third-party app’s team. There are very few apps out there that have APIs that survive the test of the complete historical data retrieval in less than 24 hours.
The workflow manager
The workflow manager delivers the automated refresh of the data pipelines built within Lokad. Data pipeline workflows in Lokad are referred to as “Project Sequences”. A project sequence can include any combination of projects, that is, scripts, external data sources and even sub-sequences. Creating a new sequence can be done from the Projects tab, using the Create project sequence button.
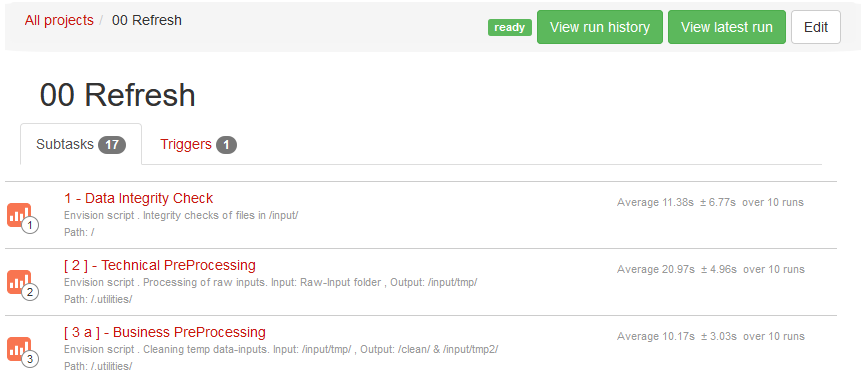
The workflow manager offers the possibility to control the degree of concurrency within the sequence, opting for either executing projects in parallel or in sequence. It also offers schedule options, and the possibility to resume - at the point of interruption - a sequence that has failed, for example because a script faced incorrect input data.
User management, ACL and SSO
Lokad is a platform intended for many-user scenarios.This includes numerous features on two fronts: authentication and authorization. On the authentication side, while Lokad supports traditional logins and passwords, we strongly suggest to leverage a federated identity management. By delegating the authentication to a third party already in place in the company, like Microsoft Office 365 or Google Apps, we entirely remove the need for the users to manage extra credentials.
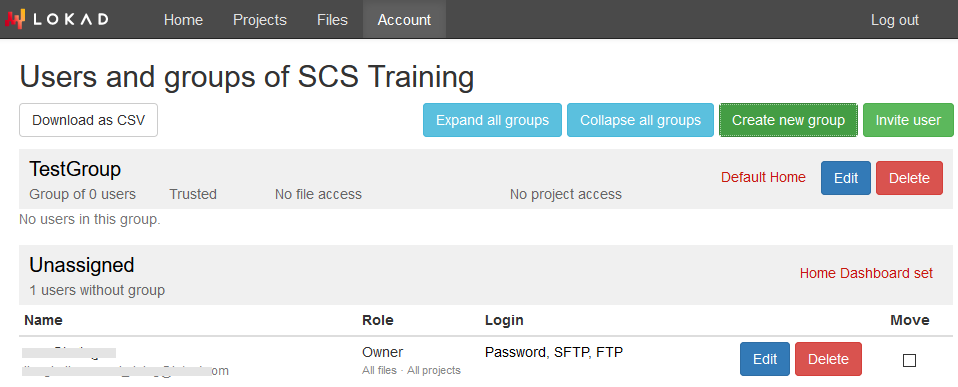
On the authorization side, Lokad features extensive Access-Control Lists (ACL). These ACLs offer a fine-grained control on who can read or write data, view or refresh dashboards, edit scripts, etc. Those fine-grained authorizations make Lokad practical to deploy even in large organizations that involve diverse audiences.